加密激励众筹:为AI模型赋能的新机遇?
-
在新冠疫情期间,Folding@home实现了一个重要里程碑,获得了2.4 exaFLOPS的计算能力,来自全球200万台志愿者设备。这一成就使其处理能力是当时世界上最大超级计算机的十五倍,极大推动了我们对COVID病毒及其病理机制的理解,尤其是在疫情初期。
深度探讨:加密激励众筹AI模型的可行性
Folding@home的成功源于其志愿计算的理念,项目通过众包计算资源解决复杂问题。这一概念早在1990年代的SETI@home项目中获得广泛认可,后者集合了超过500万台志愿计算机寻找外星生命。此后,类似的众包计算理念在天体物理学、分子生物学、数学、密码学等多个领域得到了应用,推动了科学研究的开放与合作。
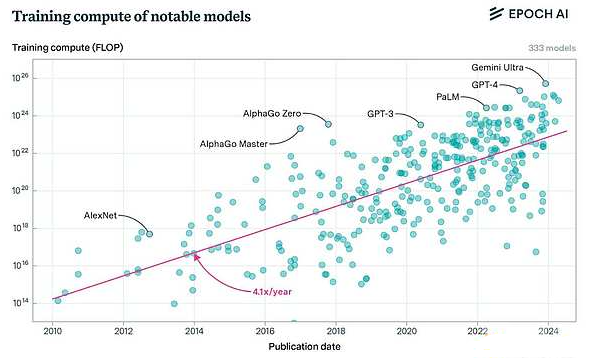
人们开始关注将这一众包模型应用于深度学习的可能性:我们是否能够在大众中训练大型神经网络?前沿模型的训练是计算密集型任务,当前成本往往高得令人难以承受,这使得只有少数大型参与者能够承担。随着技术的发展,AI系统的控制权集中在少数公司手中,这引发了人们的担忧。
尽管许多批评者认为去中心化训练的想法与现有技术不相容,但这一观点正逐渐被淘汰。新兴技术如DiLoCo、SWARM并行性、lo-fi训练等正在减少节点间的通信需求,允许在网络连接不佳的设备上进行高效训练。这些技术的进步使得去中心化网络训练变得可行。
同时,随着加密原语的成熟,全球范围内的资源协调变得更加高效。与早期的志愿项目不同,现在的网络能够汇聚巨大的计算能力,远超传统云计算集群。这些新技术为模型训练提供了新的范式,通过引入竞争机制降低训练成本,并推动协作和模块化的模型开发。
前沿模型训练的现状与挑战
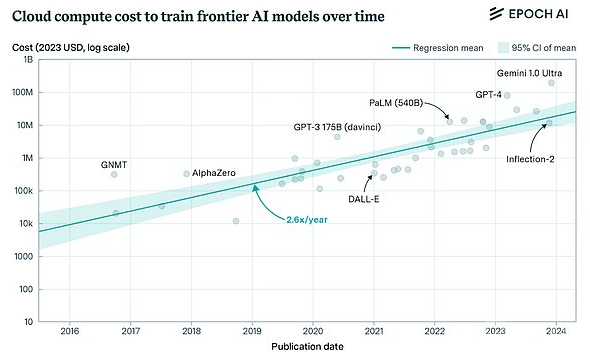
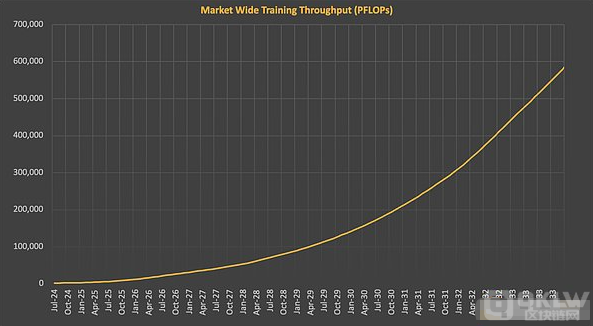
目前,前沿模型训练的成本对于非大型参与者来说已经变得难以承受。OpenAI的训练费用在今年超过了30亿美元,预计到2025年这一数字将翻倍,甚至更高。这一趋势导致行业集中化,只有少数公司能够承担这样的费用,进而控制了领先的AI系统。这种集中化不仅影响了进展速度,还限制了研究社区的创新。
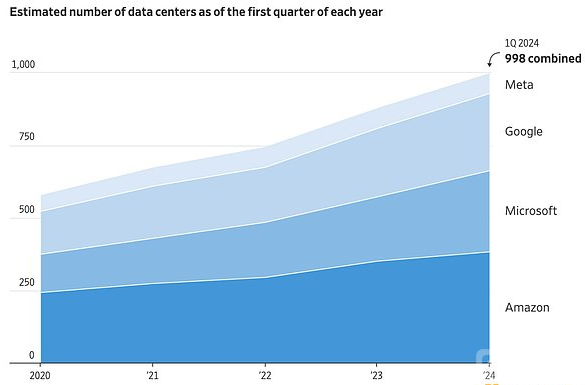
在这方面,Meta的Joe Spisak指出,理解模型架构能力需要在规模上进行探索,而许多学术机构由于缺乏计算资源而无法实现他们的想法。这种情况在小型实验室中尤为明显。
结论
为了打破这一局限,我们需要一种新的方法,通过高效利用现有基础设施,灵活扩展以应对需求波动。这将使更多实验得以进行,推动对大语言模型的突破,并向实现通用人工智能(AGI)迈进。借鉴以往的分布式计算实践,我们或许能够找到一种有效的解决方案,让更多人参与到AI模型的训练中来。

下一篇
拜登预期利率下降 比特币矿工收入依赖区块补贴
-

- 波场区块链浏览器
- 2024-09-20
- 6152
- 美国总统拜登近日表示,对抗通胀的任务尚未完成,降低借款成本将推动经济增长。他预测利率将进一步下降,认为美联储的降息标志着经济复苏进入新阶段。拜登强调尊重美联储的独立性,自入主白宫以来,他并未与美联储主席鲍威尔进行过沟通。
24小时热点
热点专题

 79010
79010