迈向用户拥有的互联网:数据DAO的未来
-
在2022年,我(Anna)提出了一种全新的用户数据拥有模型,该模型通过私人数据而非公共数据来训练基础模型。尽管可以利用公共数据(如维基百科、4Chan)来训练基础模型,但要实现更高水平的智能,需要优质的私人数据,这些数据通常存在于需要权限或登录才能访问的封闭平台(如Twitter、个人消息、公司信息)中。

数据隐私与平台控制的现状
如今,这一预测正在变成现实。Reddit和Twitter等平台已经意识到其数据的价值,因此限制了开发者访问其API(1、2),以防止其他公司使用其文本数据进行训练。这与两年前的情况截然不同。风险投资人Sam Lessin总结道:“这些平台以前就像随意丢弃垃圾,突然间意识到这些垃圾实际上是金子,于是开始锁紧垃圾箱。”例如,GPT-3曾使用WebText2进行训练,该数据汇总了Reddit中至少有三个赞的链接文本(3、4)。但使用Reddit的新API后,这种做法已不再可能。
互联网的开放性正在减少,孤立的平台正在筑起更高的围墙,以保护其宝贵的数据资源。
用户数据的潜力与挑战
尽管开发者面临访问限制,个人用户仍可以跨平台访问和导出自己的数据(5、6)。这一现象提供了一个重要机会:如果一亿用户能够导出他们的数据,就可以创建全球最大的数据宝库。这一宝库将汇总各大科技公司及其他机构收集的用户数据,这些公司通常不愿意分享这些数据。这将构建一个规模比当前领先模型大100倍的数据集(1)。
用户驱动的基础模型
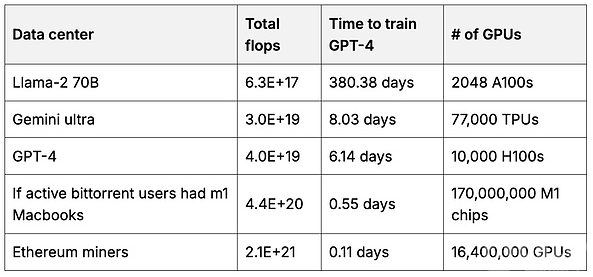
用户可以利用这些数据创建一个用户拥有的基础模型,该模型的数据量超出任何单一公司的聚合能力。虽然训练基础模型需要大量的GPU计算,但每个用户可以利用自己的硬件贡献一部分计算能力,从而集合成一个更强大的模型(7、8、9)。例如,以太坊矿工的总计算能力是目前领先基础模型训练所需计算能力的50倍。
数据DAO:重塑数据所有权
为该模型做出贡献的用户将共同拥有和管理该模型。他们可以在使用模型时获得回报,甚至可以根据其数据对模型改进的程度获得奖励。用户集体可以制定使用规则,包括访问权限和控制措施。也许每个国家的用户都会创建自己的模型,代表各自的意识形态和文化,或者形成一个全球网络国家,每个网络国家都有其基于成员数据的基础模型。
个人服务器与未来展望
我鼓励大家思考自己希望拥有哪些基础模型的一部分,以及可以贡献哪些平台数据。您可能拥有的数据比想象中的更多——您的研究论文、未发布的艺术品、Google文档、约会资料、医疗记录、Slack消息等。通过个人服务器,您可以轻松整合这些数据,与本地的LLM(大语言模型)一起使用,并在未来训练您拥有的用户基础模型的一部分。
基础模型通常垄断市场,因为它们需要大量的前期数据和计算投资。我们不应仅满足于使用过时的开源模型,而应利用我们拥有的数据和计算能力创建最优秀的模型。随着人工智能越来越能够完成有价值的经济工作,经济结构正在经历巨大的变革。大型科技公司已经通过用户数据训练人工智能模型,并从中赚取巨额利润(1)。他们正追逐那些在公共互联网无法获取的数据,如从Reddit等公司购买私人数据,以提升收入至数万亿美元(2、3)。
数据DAO的角色
您是否不希望拥有由您的数据帮助创建的AI模型的一部分?数据DAO的使命正是解决这一问题。数据DAO是一个去中心化的实体,允许用户汇集和管理自己的数据,并通过数据集特定代币奖励贡献者。它类似于数据的工会,能够创建并出售超越大型科技公司数据集的数据(4)。DAO拥有对数据集的完全控制权,可以选择出租或出售匿名副本。例如,Reddit数据可以用于创建新的用户拥有平台,包括好友、历史帖子和其他数据,这些数据可以在新平台上随时使用。
结论
数据DAO不仅使用户受益,还推动了AI的发展,使得像开源软件一样构建AI成为可能,并让所有贡献者共享收益。随着开源AI努力寻找商业模式,数据DAO的技术架构可以应用于模型DAO,用户和开发者可以通过贡献数据、计算和研究获得模型的所有权。
当前社会的默认选项是允许大型科技公司掌握我们的数据,并用这些数据训练人工智能模型,从中获利。这对社会是不利的,但对科技公司却是有利的。防止这种情况的唯一方法是集体行动。数据就是货币,集体数据就是力量。我鼓励您参与:世界上第一个专注于Reddit数据的数据DAO已在Vana网络上线。通过打破少数特权阶层对数据的控制,数据DAO开启了真正用户拥有互联网的新篇章。

下一篇
美联储意外降息50个基点:开启货币宽松新周期,未来展望复杂
-

- 波场区块链浏览器
- 2024-09-19
- 9418
- 2024年9月18日,美国时间,美联储宣布将联邦基金利率目标区间从5.25%-5.5%下调至4.75%-5%,这一举措标志着美联储自2020年3月以来首次进行大幅降息。这一决策超出市场预期,体现了美联储对当前经济形势的重大调整。
24小时热点
热点专题

 79010
79010