为什么我们看好零知识证明硬件加速?
-
本文将主要讨论 ZKP 作为扩容方案的发展现状,从理论层面描述产生证明过程中主要需要优化的几个维度,并引深到不同扩容方案对于加速的需求。然后再围绕硬件方案着重展开,展望 zk 硬件加速领域的摩尔定律。最后,关于硬件 zk 加速领域的一些机会和现状,会在文末阐述。首先,影响证明速度的主要有三个维度:证明系统,待证明电路规模,和算法软硬件优化。
对于证明系统来说,凡是使用椭圆曲线(EC)的算法,也就是市面上主流的 Groth 16(Zcash), Galo2(Scroll), Plonk(Aztec, Zksync) 这些 zk-snark 算法,产生多项式承诺的过程中涉及的大数点乘(MSM),目前都有时间长(算力要求高)的瓶颈。对于 FRI-based 算法,如 ZK-Stark,其多项式承诺产生方式是 Hash Function,不牵扯 EC,所以并不涉及 MSM 运算。
证明系统是基础,待证明电路的规模也是核心的硬件优化的需求之一。近期讨论很火的 ZKEVM 据对以太坊的兼容程度不同,导致了电路的复杂程度的不同,比如 Zksync/Starkware 构建了与原生以太坊不同的虚拟机,从而绕开了一些以太坊原生的不适合利用 zk 处理的底层代码,缩小了电路的复杂长度,而 Scroll/Hermez 这样目标从最底端兼容的 zkevm 的电路自然也会更复杂。
一个方便理解的比方是,电路的复杂性可以理解为一辆巴士上的座位,比如普通日子下需要搭载的乘客数在 30 人以下,有些巴士选择了 30 人的座位,这些巴士就是 Zksync/StarkWare,而一年中也有一些日子有特别多的乘客,一般的巴士坐不下,所以有一些巴士设计的座位更多(Scroll)。但是这些日子可能比较少,会导致平时会有很多空余的座位。
硬件加速对于这些电路设计更复杂的电路更迫切,不过这更多是一个 Specturm 的事情,对于 ZKEVM 也同样有利无弊。
不同证明系统优化的需求/侧重点:
基本:
当一个待证明事物经过电路(如 R1CS/QAP)处理之后,会得到一组标量和向量,之后被用来产生多项式或者其他形式的代数形式如 inner product argument (groth16)。这个多项式依然很冗长,如果直接生成证明那么无论是证明大小或是验证时常都很大。所以我们需要将这个多项式进一步简化。这里的优化方式叫做多项式承诺,可以理解为多项式的一种特殊的哈希值。以代数为基础的多项式承诺有 KZG, IPA,DARK,这些都是利用椭圆曲线产生承诺。
FRI 是以 Hash Function 为产生承诺的主要途径。多项式承诺的选择主要是围绕几点 - 安全性,Performance。安全性在这里主要是考虑到在 set up 阶段。如果产生 secret 所使用的 randomness 是公开的,比如 FRI,那么我们就说这个 set up 是透明的。如果产生 secret 所利用的 randomness 是私密的,需要 Prover 在使用之后就销毁,那么这个 set up 是需要被信任的。MPC 是一种解决这里需要信任的手段,但是实际应用中发现这个是需要用户来承担一定的成本。
而上述提到的在安全性方面相对卓越的 FRI 在 Performance 并不理想,同时,虽然 Pairing-friendly 椭圆曲线的 Performance 比较卓越,但是当考虑将 recursion 加入时,因适合的曲线并不多,所以也是相当大的存在相当大的 overhead。


行业现状:
当前不管是的基于 Plonk(matterlabs) 或者基于 Ultra-Plonk(Scroll, PSE),他们最后的多项式 commitment 都是基于 KZG,故而 Prover 的大部分工作都会涉及到大量的 FFT 计算 (产生多项式)和 ECC 点乘 MSM 运算(产生多项式承诺)。
在纯 plonk 模式下,由于需要 commit 的 point 数量不大,MSM 运算所占的 Prove 时间比重不高,所以优化 FFT 性能能够短期带来更大的性能提升。但是在 UltraPlonk(halo2)框架下,由于引入了 customer gate,prover 阶段设计的 commit 的 point 数量变多,使得 MSM 运算的性能优化也变得非常重要。(目前 MSM 运算进行 pippenger 优化之后,依然需要 log(P(logB)) (B 是 exp 的上界,p 是参与 MSM 的 point 的数量)。
目前新一代 Plonky2 证明系统由于所采用的多项式 commitment 不再是 KZG 而是 STARK 系统中常见的 FRI,使得 Plonky2 的 prover 不需要再考虑 MSM,从而理论上该系统的性能提升不再依赖 MSM 相关的算法优化。plonky2 的作者 Mir(目前的 Polygon Zero) 正在大力推广该系统。不过由于 plonky2 采用的数域 Goldilocks Field 对于编写 elliptic 相关的 hash 算法相关的电路(例如 ECDSA)不是特别友好,所以尽管 Goldilocks Field 在机器 word 运算方面优势明显,但是依然难以判断 Mir 和 PSE/Scroll 方案谁是更好的方案。
基于对 Plonk,Ultraplonk, Plonky2 的 Prove 算法的综合考量,需要硬件加速的模块大概率还是会集中在 FFT,MSM,HASH 三个方向。
Prover 的另一个瓶颈是 witness 的生成,通常普通非 zk 计算会略去大量的中间变量,但是在 ZK prove 的过程中,所有 witness 都需要被记录,并且会参与之后的 FFT 计算,所以如何高效的并行 witness 计算也会是 prover 矿机需要潜在考虑的方向。
加速 ZKP 方面的尝试: recursive proof - StarkNet 的 fractal L3 概念基于 recursive proof 的概念,Zksync 的 fractal hyperscaling,Scroll 也有类似的优化。
> Recursive zkSNARK 概念是对一个 Proof A 的验证过程进行证明,从而产生另一个 Proof B。只要 Verifier 能接受 B,那么相当于也接受了 A。递归 SNARK 可以也可以把多个 证明聚合在一起,比如把 A1 A2 A3 A4 的验证过程聚合为 B;递归 SNARK 也可以把一段很长的计算过程拆解为若干步,每一步的计算证明 S1 都要在下一步的计算证明中得到验证,即计算一步,验证一步,再计算下一步,这样会让 Verifier 只需要验证最后一步即可,并避免构造一个不定长的大电路的难度。
理论上 zkSNARK 都支持递归,有些 zkSNARK 方案可以直接将 Verifier 用电路实现,另一些 zkSNARK 需要把 Verifier 算法拆分成易于电路化的部分和不易电路化的部分,后者采用滞后聚合验证的策略,把验证过程放到最后一步的验证过程中。
在 L2 的未来应用上,递归的优势可以通过对于带证明事物的归纳而进一步将成本与性能等要求进一步降低。
第一种情况 (application-agnostic) 是针对不同的待证明的事物,比如一个是 state update 另一个是 Merkle Tree,这两个待证明事物的 proof 可以合并成一个 proof 但是依旧存在两个输出结果(用来分别验证的 public key)
第二种情况 (applicative recursion) 是针对同类的待证明的事物,比如两个都是 state update, 那么这两个事物可以在生成 proof 前进行聚合,且仅有一个输出结果,该结果就是经历了两次 update 的 state difference。(Zksync 的方法也类似,user cost 仅对 state difference 负责)
除了 recursive proof 以及下文主要讨论的硬件加速之外,还有其他的加速 ZKP 的方式,比如 custom gates, 移除 FFT(OlaVM 的理论基础)等,但本文因篇幅原因不予讨论。
硬件加速
硬件加速在密码学中一直是一种普遍的加速密码学证明的方式,无论是对于 RSA(RSA 的底层数学逻辑与椭圆曲线有类似之处,同样涉及了很多复杂的大数运算),还是早期对于 zcash/filecoin 的 zk-snark 的 GPU-based 的优化方式。
硬件选择
在以太坊 The Merge 发生之后,不可避免将会有大量的 GPU 算力冗余(部分受到以太坊共识改变的影响,GPU 巨头英伟达股价距年初已经跌去 50%,同时库存冗余也在不断增加),下图是英伟达 GPU 旗舰产品 RTX 3090 的成交价格,也显示买方势力较为薄弱。
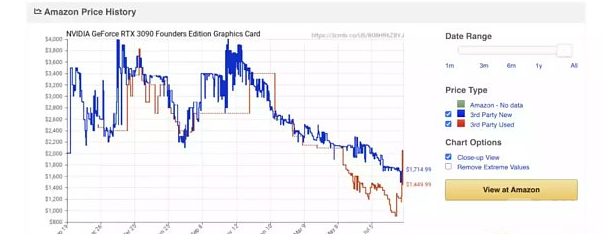
在 GPU 价格处于低点,同时大量 GPU 算力闲置,一个自然的问题就是,是否 GPU 是合适的加速 zk 的硬件呢?硬件端主要有三个选择,GPU/FPGA/ASIC。
FPGA vs GPU:
先看总结:以下是 trapdoor-tech 关于 GPU(以 Nvidia 3090 为例)以及 FPGA(Xilinx VU9P 为例)在几个维度的总结,非常重要的一点是:GPU 在性能(生成证明的速度)方面要高于 FPGA, 而 FPGA 在能源消耗则更具有优势。
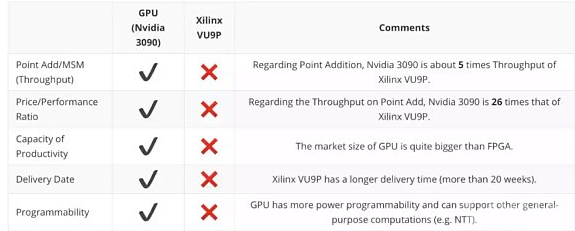
一个更直观的来自于 Ingoyama 的具体的运行结果:
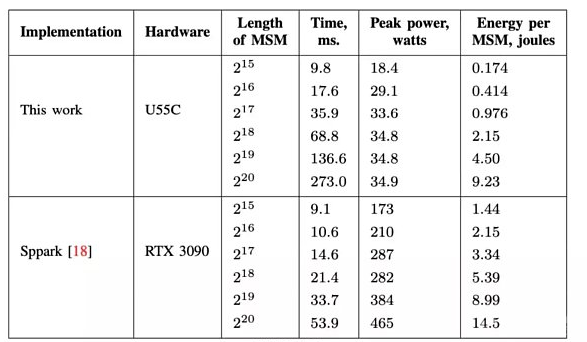
尤其是对于比特宽度更高(2^20)的运算,GPU 是 FPGA 运算速度的五倍,而消耗的电量同时也高很多。
对于普通矿工来说,性价比也是一个衡量到底使用哪一个硬件的重要的因素。无论是 U55C ($4795) 还是 VU9P ($8394) 来说,相比于 GPU (RTX 3090:$1860),价格都要高出很多。
理论层面,GPU 适合并行运算,FPGA 追求可编程性,而在零知识证明生成的环境下,这些优势并不能完美适用。比如,GPU 适用的并行计算是针对大规模图形处理,虽然逻辑上和 MSM 的处理方式类似,但是适用的范围(floating number)与 zkp 针对的特定的有限域并不一致。对于 FPGA 来说,可编程性在多个 L2 的存在的应用场景并不明朗,因为考虑到 L2 的矿工奖励与单个 L2 承接的需求挂钩(与 pow 不一样),有可能在细分赛道出现 winner takes all 的局面,导致矿工需要频繁更换算法的情景出现的可能性不高。
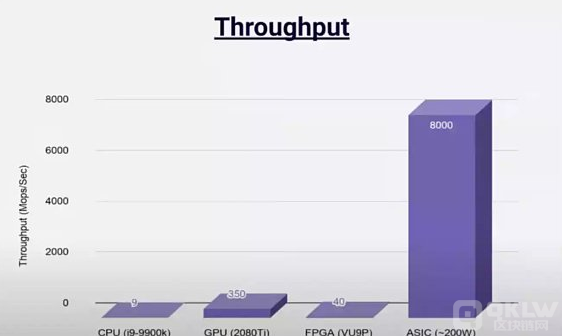
ASIC 是在性能与成本方面上权衡表现较优的方案(包括吞吐量、延迟等),但是否是最好的方案仍然没有定论,其存在的问题是:
开发时间长- 需经历完整的芯片设计到芯片生产的过程,即使目前已经设计好了芯片,芯片生产也是一个冗长、烧钱并且良片率不一的过程。代工资源方面,台积电和三星是最好的芯片代工工厂,目前台积电的订单已经排到了两年后,与 ZK 芯片竞争代工资源的是 AI 芯片、电动车芯片这类 web2 早早做好芯片设计的已经被需求证明的产品,相比之下 ZK 芯片的需求并不明朗。
其次,整颗芯片的性能和单个芯片的大小,也就是人们常说的 20nm,18nm 是成负相关的,也就是说单个芯片越小,晶片可以容纳的芯片的数量越多,即整颗的性能越高,而目前的制造高端芯片的的技术是被垄断的(比如芯片制造中最复杂的一环,光刻技术,是被荷兰的 ASML 公司垄断),对于一些中小型的代工厂(如国内的中芯国际)这类技术方面落后顶尖一到两代,也就意味着从良品率以及芯片大小方面是落后于最好的代工厂的。这会导致对于 ZK 芯片来说,只能寻求一些次优的解决方案,当然也是在需求端不那么明朗的情况下基于成本的考虑,选择 28nm 左右的非高端芯片。
目前的 ASIC 解决方案主要处理的是 FFT 以及 MSM 两个常见的 ZK 电路中算力需求比较高的算子,并不是针对具体的一个项目设计的,所以具体运行的效率并不是理论上最高的。比如,目前 Scroll 的 prover 的逻辑电路还没百分百实现,自然也不存在与之一一匹配的硬件电路。并且,ASIC 是 application-specific,并不支持后续的调整,当逻辑电路发生了变化,比如节点的客户端需要升级,是否存在一个方案也可以兼容,也是目前不确定的。
同时,人才缺失也是 ZK 芯片的一个行业现状,理解密码学和硬件的人才并不好找,合适的人选是有同时具备较深的数学造诣以及多年的硬件产品设计以及维护经验。
Closing thoughts - prover 发展趋势 EigenDA
以上都是行业对于加速 ZKP 的思考与尝试,最终意义就是运行 prover 的门槛会越来越低。周期性来讲 prover 需要经历大致的如下三个阶段:
Phase I: Cloud-based prover
基于云的 prover 可以大大提高第三方 prover(非用户/项目方)的准入门门槛,类似于 web2 的 aws/google cloud。商业模式上来讲,项目方会流失一部分奖励,但是从去中心化的叙事讲这是一种经济以及执行层面吸引更多参与者的方式。而云计算/云服务是 web2 现有的技术栈,已有成熟的开发环境可供开发者使用,并且可以发挥云所特有的低门槛/高集群效应,对于短期内的 proof outsource 是一种选择。
目前,Ingoyama 也有在这一方面的实现(最新的 F1 版甚至达到了 pipeMSM 的基准速度的两倍)。但是,这依然是一个单个 prover 运行整个 proof 的方式,而在 phase II 中 proof 可以是一种可拆分的形式存在,参与者数量会更多。
Phase II: Prover marketplace
proof 生成的过程中包含不同的运算,有的运算对于效率有偏好,有的运算则对成本/能源消耗有要求。比如 MSM 计算涉及 pre-computation,这需要一定的 memory 支持不同的 pre-computation 上的标量颗粒,而如果所有的标量都存在一个计算机上的话对于该计算机的 memory 要求较高,而如果将不同的标量存储在多个服务器上,那么不仅该类的计算的速度会提高,并且参与者的数量也会增加。
Marketplace 是一种针对上述外包计算的一种商业模式上的大胆的思考。但其实在 Crypto 圈子里也有先例 - Chainlink 的预言机服务,不同链上的不同交易对的价格喂送也是以一种 marketplace 的形式存在。同时,Aleo 的创始人 Howard Wu 曾经合作撰写过一篇 DIZK,是一个分布式账本的零知识证明生成方法论,理论上是可行的。
话说回来,商业模式上讲这是一种非常有意思的思考,但是可能在实际落地时一些执行上的困难也是巨大的,比如这类运算之间如何协调生成完整的 proof,至少需要在时间以及成本上不落后于 Phase I。
Phase III: Everyone runs prover
未来 Prover 会运行在用户本地(网页端或者移动端),如 Zprize 有基于 webassembly/andriod 执行环境的 ZKP 加速相关的竞赛和奖励,意味着一定层面上用户的隐私会得到确保(目前的中心化 prover 只是为了扩容,并不保证用户隐私),最重要的上 - 这里的隐私不仅局限于链上行为,也包括链下行为。
一个必须要考虑的问题是关于网页端的安全性,网页端的执行环境相比硬件来说对于安全性的先决条件更高(一个 industry witness 是 metmask 这样的网页端钱包相比于硬件钱包,安全性更低)。
除了链上数据链下证明外,以 ZKP 的形式将链下数据上传到链上,同时百分百保护用户隐私,也只有在这个 Phase 可能成立。目前的解决方案都难免面临两个问题 - 1. 中心化,也就是说用户的信息依然有被审查的风险 2. 可验证的数据形式单一。因为链下数据形式多样且不规范化,可验证的数据形式需要经过大量的清洗/筛查,同时依旧形式单一。
这里的挑战甚至不只是证明生成的环境,对于算法层面是否有能够兼容(首先必须使用 transparent 的算法),以及成本/时间/效率都是需要思考的。但是同样需求也是无与伦比的,想象可以以去中心化的方式抵押现实生活的信用在链上进行借贷,并且不会有被审查的风险。


下一篇
Andre Cronje系列定义
-

- 嗨艺购
- 2022-05-16
- 31534
- Andre Cronje系列定义 Andre Cronje(AC) 是 yearn.finance(YFI)创始人,加密媒体Crypto Briefing
24小时热点
热点专题

 2387813
2387813