

大模型不是一跃而起的
大模型发展的前期被称为预训练模型,预训练技术的主要思想是迁移学习。当目标场景的数据不足时,首先在数据量庞大的公开数据集上训练模型,然后将其迁移到目标场景中,通过目标场景中的小数据集进行微调 ,使模型达到需要的性能 。在这一过程中,这种在公开数据集训练过的深层网络模型,被称为“预训练模型”。使用预训练模型很大程度上降低下游任务模型对标注数据数量的要求,从而可以很好地处理一些难以获得大量标注数据的新场景。
2018年出现的大规模自监督(self-supervised)神经网络是真正具有革命性的。这类模型的精髓是从自然语言句子中创造出一些预测任务来,比如预测下一个词或者预测被掩码(遮挡)词或短语。这时,大量高质量文本语料就意味着自动获得了海量的标注数据。让模型从自己的预测错误中学习10亿+次之后,它就慢慢积累很多语言和世界知识,这让模型在问答或者文本分类等更有意义的任务中也取得好的效果。没错,说的就是BERT 和GPT-3之类的大规模预训练语言模型,也就是我们说的大模型。
2.5 为什么大模型有革命性意义?
突破现有模型结构的精度局限
2020年1月,OpenAI发表论文[3],探讨模型效果和模型规模之间的关系。
结论是:模型的表现与模型的规模之间服从Power Law,即随着模型规模指数级上升,模型性能实现线性增长

2022年8月,Google发表论文[4],重新探讨了模型效果与模型规模之间的关系。
结论是:当模型规模达到某个阈值时,模型对某些问题的处理性能呈现快速增长。作者将这种现象称为Emergent Abilities,即涌现能力。

预训练大模型+细分场景微调更适合长尾落地
用著名NLP学者斯坦福大学的Chris Manning教授[2]的话来说,在未标注的海量语料上训练大模型可以:
Produce one large pretrained model that can be very easily adapted, via fine-tuning or prompting, to give strong results on all sorts of natural language understanding and generation tasks.
通过微调或提示,大规模预训练模型可以轻松地适应各种自然语言理解和生成任务,并给出非常强大的结果。
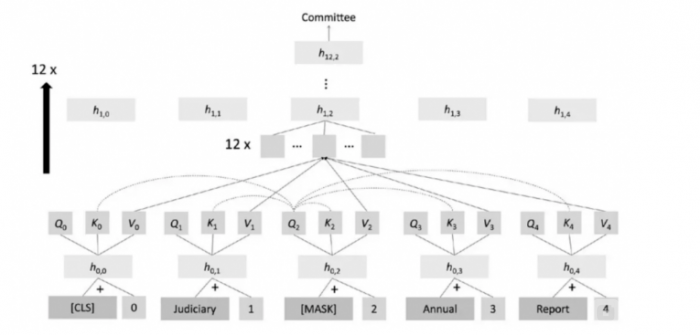
Transformer 架构自2018年开始统治NLP领域,NLP领域的进展迎来了井喷。为何预训练的transformer有如此威力?其中最重要的思想是attention,也就是注意力机制。Attention其实非常简单,就是句子中每个位置的表征(representation,一般是一个稠密向量)是通过其他位置的表征加权求和而得到。Transformer模型通过每个位置的query, key以及value的表征计算来预测被掩码位置的单词,大致过程如下图所示,更具体的细节这里不再赘述。
2.6 为什么这么简单的结构和任务能取得如此威力?
原因在其通用性。
预测下一个单词这类任务简单且通用,以至于几乎所有形式的语言学和世界知识,从句子结构、词义引申、基本事实都能帮助这个任务取得更好的效果。大模型也在训练过程中学到了这些信息,让单个模型在接收少量的指令后就能解决各种不同的NLP问题。也许,大模型就是“大道至简”的最好诠释。
基于大模型完成多种NLP任务,在2018年之前靠fine-tuning(微调),也就是在少量针对任务构建的有监督数据上继续训练模型。后来则出现了prompt(提示学习)这种形式,只需要对任务用语言描述或者给几个例子,模型就能很好的执行以前从未训练过的任务。
大模型还改变了NLP的范式
传统的NLP是流水线范式:先做词法(如分词、命名实体识别)处理,再做句法处理(如自动句法分析等),然后再用这些特征进行领域任务(如智能问答、情感分析)。这个范式下,每个模块都是由不同模型完成的,并需要在不同标注数据集上训练。而大模型出现后,就完全代替了流水线模式,比如:
更值得一提的是 NLG (natural language generation),大模型在生成通顺文本上取得了革命性突破,对于这一点玩过ChatGPT的同学一定深有体会。
大模型能在NLP任务上取得优异效果是毋庸置疑的,但我们仍然有理由怀疑大模型真的理解语言吗,还是说它们仅仅是鹦鹉学舌?
2.7 大模型能真正理解人类语言吗?
要讨论这个问题,涉及到什么是语义,以及语言理解的本质是什么。关于语义,语言学和计算机科学领域的主流理论是指称语义(denotational semantics),是说一个单词短语或句子的语义就是它所指代的客观世界的对象。与之形成鲜明对比的是,深度学习NLP遵循的分布式语义(distributional semantics),也就是单词的语义可以由其出现的语境所决定。
Meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms.
意义来源于理解语言形式与其他事物之间的连接,无论它们是语言形式还是世界上其他的物体。
引用NLP大佬Manning的原话,用对语言形式之间的连接来衡量语义的话,现在的大模型对语言的理解已经做的很好了。但局限性在于,这种理解仍然缺乏世界知识,也需要用其他模态的感知来增强,毕竟用语言对图像和声音等的描述,远不如这些信号本身来的直接。(没错,GPT-4!)





















 2761286
2761286